



ARAHNESIA.ID – Pada awalnya, Komputer dibangun untuk menghitung. Namun, 1960-an Para ahli sudah mulai berfikir mengenai fungsi komputer yang lain, yang lebih luas. Para Ilmuan berusaha untuk membuat komputer bisa lebih cerdas dengan membuat komputer bisa belajar dari sejumlah data atau pengalaman.
Definisi Komputer dapat Belajar
Menurut Tom M. Mitchell (1997), sebuah program komputer disebut belajar jika:
- Ia memiliki pengalaman (E),
- Mengerjakan tugas tertentu (T),
- Dan memiliki ukuran penilaian kinerja (P),
Lalu kinerjanya pada tugas tersebut meningkat seiring bertambahnya pengalaman. Dengan kata lain, komputer dianggap belajar jika ia menjadi lebih baik dalam suatu tugas setelah mendapatkan lebih banyak pengalaman.
Berdasarkan definisi Tom M. Mitchell, muncul pertanyaan: apakah komputer bisa dibuat agar mampu belajar dari pengalaman?
Pada awal pembuatan komputer di tahun 1940-an, para ahli hanya fokus membuat mesin yang bisa menghitung dengan sangat cepat. Banyak teknik dan metode komputasi dikembangkan, tetapi belum ada pemikiran untuk membuat komputer yang bisa belajar seperti manusia.
Pada masa itu, komputer hanya menjalankan perintah yang sudah ditentukan, bukan memperbaiki dirinya sendiri. Ide tentang program yang membuat komputer semakin pintar dari pengalaman baru berkembang jauh setelahnya, ketika konsep machine learning mulai muncul.
Sejak tahun 1980-an hingga sekarang, banyak program komputer yang sudah mampu belajar secara otomatis. Beberapa contoh pentingnya adalah:
- ALVINN (Autonomous Land Vehicle in Neural Networks)
Ini adalah kendaraan yang bisa belajar dari cara mengemudi manusia. Setelah dilatih beberapa menit menggunakan metode Artificial Neural Networks (ANN), ALVINN dapat berjalan sendiri tanpa sopir hingga 80 km/jam (Pomerleau 1989). - ImageNet
Merupakan basis data berisi jutaan gambar yang dikelompokkan ke dalam ribuan kategori. Dataset ini digunakan untuk melatih sistem machine learning berskala besar agar mampu melakukan klasifikasi gambar dengan akurasi tinggi. Sejak 2010, ImageNet telah melahirkan ratusan model komputer yang bisa mengenali dan mengelompokkan gambar secara otomatis (VisionLab 2017). - Dragon Speak
Sebuah program yang dapat belajar mengenali suara manusia dan mengubahnya menjadi teks dengan akurasi sangat tinggi (Nuance 2017).
Dengan terus berkembangnya teknologi perangkat keras dan internet of things (IoT), kemampuan komputer untuk belajar diprediksi akan semakin maju dan cepat di masa depan.
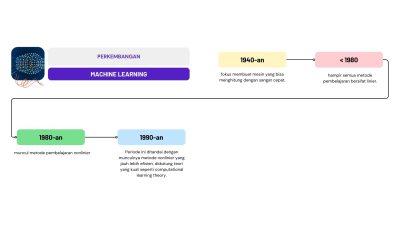
Era Machine Learning
Walaupun machine learning berkembang pesat setelah tahun 1980-an, dasar-dasar teorinya sudah muncul jauh sebelumnya. Perkembangannya dapat dibagi menjadi tiga era utama:
1. Era Sebelum 1980
Pada masa ini, hampir semua metode pembelajaran bersifat linier. Tujuannya adalah membuat aturan atau batas keputusan yang sederhana. Kelebihannya, metode-metode ini sudah memiliki dasar teori yang kuat, tetapi kemampuan belajarnya masih terbatas.
2. Era 1980-an
Di era ini muncul metode pembelajaran nonlinier, seperti:
- Decision Trees
- Artificial Neural Networks (ANN)
Keduanya membuka peluang baru dalam mempelajari data yang lebih kompleks. Namun pada saat itu, teori pendukungnya masih belum kokoh, dan model sering terjebak pada optimum lokal (solusi terbaik yang sebenarnya bukan yang paling optimal).
3. Era 1990-an hingga Sekarang
Periode ini ditandai dengan munculnya metode nonlinier yang jauh lebih efisien, didukung teori yang kuat seperti computational learning theory. Metode-modern ini lebih stabil, lebih akurat, dan cocok untuk dataset besar, inilah fondasi machine learning modern yang kita gunakan sekarang.
Klasifikasi Metode Machine Learning
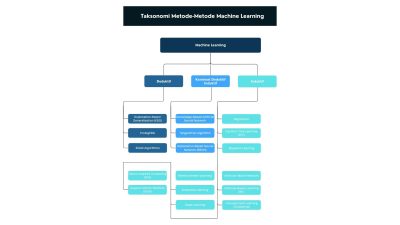
Metode machine learning dapat diklasifikasikan dengan banyak cara:
- berdasarkan dampak bagi pengguna,
- berdasarkan jenis input–output (diskrit atau kontinu),
- berdasarkan cara kerja (offline atau online),
- berdasarkan kemudahan interpretasi
- atau berdasarkan metode penalarannya (induktif atau deduktif).
Pada bagian ini, klasifikasi dijelaskan berdasarkan dampak yang diharapkan oleh pengguna.
Berdasarkan Dampak yang Diharapkan
Secara umum, ada enam kelompok utama algoritma machine learning:
Supervised Learning (Pembelajaran Terawasi)
Algoritma ini belajar dari pasangan input–output yang telah disiapkan oleh pengguna (data berlabel).
- Tugas: Membuat fungsi yang memetakan input ke output yang benar.
- Contoh Masalah: Klasifikasi (Menentukan apakah sebuah gambar termasuk kategori kucing, anjing, atau burung berdasarkan contoh-contoh sebelumnya) dan Regresi.
Unsupervised Learning (Pembelajaran Tanpa Pengawasan)
Pada metode ini, tidak ada output atau label yang diberikan. Algoritma hanya menerima data input dan mencoba menemukan pola-pola tersembunyi di dalamnya.
- Penggunaan Umum: Clustering (pengelompokan).
- Contoh: Mengelompokkan pelanggan berdasarkan kebiasaan belanja, tanpa ada label kelas yang telah ditentukan.
Semi-supervised Learning
Metode ini menggabungkan supervised dan unsupervised learning.
- Prinsip: Sebagian data memiliki label, sebagian lainnya tidak.
- Keuntungan: Algoritma memanfaatkan seluruh data (baik berlabel maupun tidak) untuk menghasilkan model yang lebih baik dibanding hanya menggunakan data berlabel saja.
- Cocok Untuk: Situasi ketika proses pelabelan mahal atau memakan waktu, tetapi banyak data tanpa label tersedia.
Reinforcement Learning
Algoritma belajar melalui interaksi dengan lingkungan.
- Mekanisme: Setiap aksi menghasilkan akibat. Lingkungan memberikan reward atau penalti sebagai umpan balik.
- Tujuan: Menemukan kebijakan terbaik untuk memaksimalkan reward jangka panjang.
- Contoh: Robot belajar berjalan, atau AI yang belajar bermain game (AlphaGo, dll.).
Transduction
Mirip dengan supervised learning, tetapi tidak membuat fungsi umum (model prediksi jangka panjang).
- Fokus: Algoritma langsung memprediksi output untuk data baru menggunakan data training yang ada.
- Prinsip: Memanfaatkan hubungan langsung antar data daripada membangun model yang dapat menggeneralisasi untuk semua input di masa depan.
Berdasarkan jenis input dan output
Metode machine learning dapat dibedakan berdasarkan jenis input dan output yang digunakan, yaitu diskrit dan kontinu.
Apa bedanya?
- Diskrit → data berupa kategori atau nilai yang terpisah (misalnya: “merah”, “biru”, “ya/tidak”, “kelas A/B/C”).
- Kontinu → data berupa angka yang nilainya bisa berubah secara halus dan tidak terhingga (misalnya: suhu, berat, waktu, harga).
Beberapa algoritma pembelajaran dirancang untuk menerima data diskrit dan menghasilkan output diskrit. Data diskrit biasanya memiliki nilai yang terpisah dan terbatas, misalnya kategori warna (merah, biru, hijau) atau kelas objek (kucing, anjing, burung). Contoh algoritma yang bekerja dengan baik pada data jenis ini adalah Decision Tree Learning (DTL). Algoritma ini membagi data berdasarkan kondisi-kondisi diskrit untuk menentukan kelas output.
Di sisi lain, ada algoritma yang bekerja dengan data kontinu, yaitu data yang nilainya dapat berubah dalam rentang tertentu, seperti suhu, berat, atau waktu. Algoritma seperti Artificial Neural Networks (ANN) termasuk dalam kelompok ini. ANN dapat menerima input kontinu dan menghasilkan output yang bisa berupa nilai kontinu maupun kelas diskrit, tergantung kebutuhan.
Beberapa algoritma lain, seperti Support Vector Machine (SVM), menerima input kontinu tetapi menghasilkan output diskrit, biasanya dua kelas (misalnya positif atau negatif). Karena input-nya berupa data kontinu, SVM digolongkan sebagai algoritma pembelajaran kontinu.
Dalam memilih metode, kuncinya adalah melihat jenis data dan jenis output yang dibutuhkan.
- Jika data Anda diskrit dan output yang Anda inginkan juga diskrit, maka gunakan algoritma pembelajaran diskrit.
- Jika data Anda kontinu, dan Anda ingin output yang bisa berupa diskrit atau kontinu, maka gunakan algoritma pembelajaran kontinu.
Cara memilihnya cukup sederhana: sesuaikan algoritma dengan karakteristik data dan hasil yang ingin Anda capai.
Berdasarkan Cara Kerjanya
Algoritma pembelajaran juga dapat dibedakan berdasarkan cara kerjanya, yaitu offline learning dan online learning. Keduanya memiliki mekanisme dan kegunaan yang berbeda.
Pada offline learning, proses pembelajaran dilakukan sekali di awal menggunakan sebagian atau seluruh data yang tersedia. Setelah model selesai dibangun, model tersebut digunakan untuk memprediksi data di masa depan.
Metode ini biasanya memberikan kinerja yang sangat baik pada data awal yang digunakan saat pelatihan. Namun, seiring berjalannya waktu, performanya bisa menurun karena model tidak mengetahui adanya perubahan pola data yang baru.
Jika performa model sudah tidak lagi akurat, barulah dilakukan pelatihan ulang (retraining) menggunakan data terbaru. Artinya, pembaruan hanya dilakukan jika memang diperlukan.
Sebaliknya, online learning bekerja dengan cara memperbarui model secara berkelanjutan setiap kali data baru masuk. Model tidak dilatih dari nol seperti pada offline learning, melainkan di-update terus-menerus berdasarkan informasi terbaru. Pendekatan ini membuat model selalu relevan dengan kondisi saat ini, tanpa perlu retraining yang memakan waktu.
Sebagai contoh, bayangkan Anda membangun sistem pendeteksi berita hoaks. Jika Anda menggunakan offline learning, Anda bisa melatih model menggunakan data berita hoaks selama satu tahun terakhir, misalnya dari Agustus 2016 hingga Juli 2017. Model ini mungkin bekerja sangat baik pada bulan Agustus 2017, tetapi performanya akan mulai turun pada bulan September dan bulan-bulan berikutnya. Penyebabnya jelas: isu berita berubah sangat cepat, sehingga model lama tidak lagi sesuai dengan pola berita terbaru.
Namun, jika Anda menggunakan online learning, model akan diperbarui setiap hari menggunakan berita terbaru yang masuk. Dengan demikian, model akan selalu selaras dengan perkembangan isu dan mampu mendeteksi berita hoaks secara akurat kapan pun.
Lalu, mana yang lebih baik?
Offline learning biasanya lebih cepat konvergen dan sering memberi performa lebih stabil pada data yang homogen. Namun, jika jumlah data sangat besar atau terus bertambah hingga tidak muat dalam memori, online learning menjadi pilihan yang lebih efisien karena dapat belajar dari data secara bertahap tanpa perlu memproses semuanya sekaligus.
Berdasarkan kemudahan interpretasinya
Metode machine learning juga dapat dibedakan berdasarkan kemudahan interpretasi, yaitu apakah model yang dihasilkan mudah dipahami atau sulit dijelaskan kepada pengguna.
Beberapa algoritma menghasilkan model yang sangat mudah dipahami. Misalnya, Decision Tree Learning menghasilkan aturan-aturan sederhana yang dapat dibaca seperti “Jika A maka B”. Struktur pohonnya jelas, sehingga pengguna dapat melihat alasan mengapa suatu keputusan dibuat.
Sebaliknya, ada algoritma yang menghasilkan model yang sulit diinterpretasikan. Contohnya, Artificial Neural Networks (ANN) mempelajari pola data melalui bobot-bobot matematis yang tidak dapat dijelaskan secara intuitif. Begitu pula dengan Support Vector Machine (SVM), yang hanya menghasilkan support vectors—elemen yang menentukan batas keputusan tetapi tidak mudah dijelaskan kepada pengguna biasa. Model-model seperti ini sering disebut sebagai black box karena cara kerjanya tidak langsung terlihat.
Dalam banyak kasus, model yang mudah diinterpretasikan memiliki performa sedikit lebih rendah, sedangkan model yang sulit diinterpretasikan sering memberikan akurasi lebih tinggi. Karena itu, pemilihannya sangat bergantung pada kebutuhan.
Di bidang seperti medis, kebijakan publik, atau situasi yang membutuhkan penjelasan yang jelas kepada manusia, model yang mudah dipahami seperti decision tree lebih disukai. Penjelasan yang transparan sangat penting untuk membangun kepercayaan dan memastikan keputusan dapat dipertanggungjawabkan.
Sebaliknya, di bidang seperti engineering, riset, atau aplikasi yang mengutamakan presisi dan akurasi tinggi, model yang sulit diinterpretasikan seperti ANN dan SVM lebih banyak dipilih. Dalam konteks ini, performa menjadi prioritas utama, dan keterbatasan interpretasi dianggap dapat diterima.
Singkatnya: pilih model yang mudah dijelaskan ketika transparansi penting, dan pilih model yang lebih kompleks ketika akurasi adalah tujuan utama.
Berdasarkan Cara Penalarannya
Metode machine learning juga dapat dibedakan berdasarkan cara penalarannya, yaitu apakah menggunakan penalaran induktif atau penalaran deduktif. Untuk memahaminya, kita perlu mengenal dulu makna dari inference atau inferensi.
Kata inference berasal dari kata kerja infer, yang menurut Oxford Learner’s Dictionary berarti menarik kesimpulan berdasarkan informasi atau bukti yang tersedia. Dengan kata lain, inferensi adalah proses menggunakan data atau fakta untuk menghasilkan sebuah keputusan atau kesimpulan.
Dalam dunia penalaran, terdapat dua pendekatan utama:
- Penalaran Induktif
Penalaran ini menghasilkan kesimpulan berdasarkan banyak pengamatan (multiple observations).
Misalnya, setelah melihat ribuan contoh data, sebuah model menyimpulkan pola tertentu.
Inilah cara kerja sebagian besar algoritma machine learning: mereka belajar dari contoh untuk menemukan pola umum. - Penalaran Deduktif
Pada penalaran deduktif, kesimpulan diperoleh berdasarkan premis-premis atau aturan yang sudah pasti dan logis.
Contohnya:- Premis: Semua burung dapat terbang.
- Premis: Merpati adalah burung.
- Kesimpulan: Merpati dapat terbang.
- Premis: Semua burung dapat terbang.
Machine learning modern didominasi oleh metode induktif, karena teknik ini mampu mempelajari pola dari data dalam jumlah besar—sesuatu yang sangat dibutuhkan di era ledakan data saat ini. Semakin besar dan kompleks data yang tersedia, semakin penting model yang bisa belajar secara cepat, otomatis, dan adaptif, dan itulah kekuatan utama penalaran induktif.
Singkatnya:
- Induktif = belajar dari banyak contoh → cocok untuk big data dan fenomena yang berubah-ubah.
- Deduktif = menarik kesimpulan dari aturan logis → cocok untuk sistem berbasis aturan.